| SPID | Taxonomy | F27446.S01 | F27446.S02 | F27446.S03 | F27446.S04 | F27446.S05 | F27446.S06 | F27446.S07 | F27446.S08 | F27446.S09 | F27446.S10 | F27446.S11 | F27446.S12 |
|---|
| SP1 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;sp. HMT780 | 31 | 0 | 13 | 74 | 135 | 26 | 5 | 0 | 5 | 70 | 116 | 86 |
|---|
| SP10 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;flavescens | 1817 | 0 | 0 | 0 | 0 | 0 | 3327 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP100 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT300 | 0 | 0 | 0 | 0 | 32 | 0 | 11 | 204 | 14 | 41 | 21 | 23 |
|---|
| SP101 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;sp. HMT277 | 0 | 0 | 72 | 2 | 0 | 25 | 0 | 0 | 59 | 1 | 0 | 181 |
|---|
| SP102 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Mogibacterium;diversum | 11 | 13 | 7 | 68 | 14 | 85 | 10 | 0 | 9 | 38 | 20 | 45 |
|---|
| SP105 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Stomatobaculum;longum | 0 | 122 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP108 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;shahii | 45 | 0 | 404 | 2163 | 0 | 233 | 107 | 0 | 273 | 1067 | 0 | 125 |
|---|
| SP109 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;gingivalis | 9 | 11 | 180 | 390 | 43 | 26 | 42 | 21 | 189 | 180 | 0 | 20 |
|---|
| SP11 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;sp. HMT138 | 0 | 0 | 7 | 0 | 0 | 3 | 0 | 110 | 54 | 0 | 0 | 112 |
|---|
| SP110 | Bacteria;Synergistetes;Synergistia;Synergistales;Synergistaceae;Fretibacterium;fastidiosum | 3 | 30 | 0 | 8 | 0 | 0 | 29 | 437 | 11 | 9 | 4 | 0 |
|---|
| SP112 | Bacteria;Bacteroidetes;Bacteroidetes_[C-1];Bacteroidetes_[O-1];Bacteroidetes_[F-1];Bacteroidetes_[G-3];bacterium HMT365 | 7 | 0 | 0 | 10 | 0 | 0 | 18 | 33 | 0 | 19 | 0 | 0 |
|---|
| SP114 | Bacteria;Actinobacteria;Actinomycetia;Micrococcales;Micrococcaceae;Rothia;aeria | 478 | 241 | 163 | 31 | 352 | 117 | 378 | 124 | 101 | 41 | 15 | 97 |
|---|
| SP115 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;histicola | 0 | 1265 | 0 | 17 | 690 | 690 | 0 | 54 | 0 | 12 | 247 | 383 |
|---|
| SP116 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Megasphaera;micronuciformis | 6 | 57 | 0 | 12 | 30 | 237 | 6 | 5 | 0 | 5 | 53 | 158 |
|---|
| SP118 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Aggregatibacter;sp. HMT949 | 0 | 0 | 5 | 0 | 93 | 0 | 0 | 0 | 0 | 0 | 27 | 0 |
|---|
| SP119 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;downii | 1386 | 33 | 228 | 52 | 107 | 0 | 938 | 29 | 471 | 118 | 38 | 0 |
|---|
| SP12 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;buccalis | 216 | 125 | 595 | 86 | 1660 | 119 | 171 | 376 | 304 | 107 | 303 | 702 |
|---|
| SP120 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT417 | 265 | 732 | 47 | 5371 | 0 | 549 | 905 | 527 | 40 | 2239 | 0 | 333 |
|---|
| SP121 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;gordonii | 123 | 260 | 6 | 23 | 276 | 13 | 227 | 225 | 8 | 36 | 125 | 81 |
|---|
| SP122 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptostreptococcus;stomatis | 28 | 9 | 143 | 632 | 0 | 152 | 26 | 0 | 192 | 322 | 7 | 221 |
|---|
| SP124 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Oribacterium;parvum | 0 | 0 | 102 | 323 | 0 | 0 | 32 | 0 | 47 | 219 | 0 | 0 |
|---|
| SP125 | Bacteria;Actinobacteria;Actinomycetia;Propionibacteriales;Propionibacteriaceae;Arachnia;rubra | 0 | 45 | 16 | 3 | 0 | 7 | 0 | 26 | 8 | 14 | 0 | 22 |
|---|
| SP126 | Bacteria;Actinobacteria;Actinomycetia;Propionibacteriales;Propionibacteriaceae;Arachnia;propionica | 404 | 78 | 45 | 37 | 286 | 21 | 304 | 295 | 31 | 303 | 78 | 150 |
|---|
| SP127 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;leadbetteri | 58 | 17 | 954 | 1337 | 535 | 176 | 126 | 77 | 768 | 863 | 54 | 360 |
|---|
| SP128 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Weeksellaceae;Riemerella;sp. HMT322 | 109 | 30 | 337 | 348 | 202 | 40 | 103 | 38 | 219 | 220 | 47 | 125 |
|---|
| SP129 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;tobetsuensis | 99 | 0 | 334 | 1611 | 0 | 0 | 124 | 0 | 363 | 807 | 0 | 0 |
|---|
| SP130 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Aggregatibacter;sp. HMT898 | 43 | 4 | 0 | 0 | 0 | 0 | 51 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP131 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;saccharolytica | 3 | 15 | 31 | 0 | 24 | 12 | 22 | 135 | 42 | 15 | 20 | 254 |
|---|
| SP132 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Ruminococcaceae;Ruminococcaceae_[G-1];bacterium HMT075 | 81 | 40 | 497 | 217 | 188 | 117 | 56 | 89 | 181 | 155 | 26 | 290 |
|---|
| SP133 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sp. HMT412 | 11 | 39 | 0 | 6 | 0 | 0 | 5 | 87 | 0 | 13 | 0 | 0 |
|---|
| SP134 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;constellatus | 8 | 49 | 0 | 4 | 0 | 0 | 3 | 163 | 0 | 11 | 0 | 19 |
|---|
| SP135 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;intermedia | 325 | 68 | 39 | 0 | 0 | 117 | 1505 | 457 | 101 | 285 | 0 | 0 |
|---|
| SP136 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lachnospiraceae_[G-3];bacterium HMT100 | 10 | 10 | 177 | 414 | 51 | 11 | 0 | 52 | 139 | 239 | 12 | 152 |
|---|
| SP137 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Aerococcaceae;Abiotrophia;defectiva | 167 | 234 | 399 | 36 | 951 | 55 | 133 | 162 | 204 | 43 | 119 | 371 |
|---|
| SP138 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;endodontalis | 31 | 14 | 116 | 0 | 14 | 17 | 119 | 40 | 111 | 24 | 0 | 160 |
|---|
| SP139 | Bacteria;Proteobacteria;Betaproteobacteria;Burkholderiales;Burkholderiaceae;Lautropia;mirabilis | 433 | 466 | 1059 | 316 | 5190 | 899 | 245 | 483 | 691 | 154 | 179 | 2579 |
|---|
| SP14 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;sp. HMT203 | 177 | 6 | 57 | 0 | 4 | 0 | 479 | 149 | 74 | 40 | 315 | 300 |
|---|
| SP140 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;pasteri | 745 | 215 | 2346 | 2822 | 544 | 202 | 1324 | 130 | 1714 | 1817 | 68 | 736 |
|---|
| SP141 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Kingella;oralis | 0 | 99 | 0 | 0 | 207 | 8 | 31 | 91 | 0 | 8 | 51 | 31 |
|---|
| SP142 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Tannerellaceae;Tannerella;sp. HMT286 | 43 | 15 | 14 | 0 | 47 | 56 | 20 | 131 | 0 | 0 | 10 | 116 |
|---|
| SP143 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;haemolytica | 6 | 123 | 0 | 3 | 81 | 0 | 11 | 420 | 4 | 17 | 49 | 24 |
|---|
| SP145 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;parvula | 28 | 105 | 17 | 11 | 369 | 195 | 38 | 281 | 14 | 46 | 166 | 193 |
|---|
| SP146 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;dispar | 220 | 1545 | 112 | 67 | 332 | 421 | 214 | 551 | 161 | 33 | 183 | 373 |
|---|
| SP147 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;loescheii | 0 | 0 | 0 | 0 | 18 | 0 | 0 | 75 | 0 | 0 | 5 | 16 |
|---|
| SP148 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Schaalia;odontolytica | 203 | 725 | 735 | 2839 | 190 | 3111 | 294 | 73 | 961 | 1367 | 30 | 858 |
|---|
| SP149 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;denticola | 7 | 14 | 9 | 12 | 0 | 10 | 154 | 285 | 10 | 40 | 42 | 0 |
|---|
| SP15 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;timonensis | 0 | 0 | 2 | 0 | 1 | 0 | 37 | 0 | 21 | 0 | 4 | 25 |
|---|
| SP150 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Pseudoleptotrichia;sp. HMT221 | 9 | 0 | 1573 | 2841 | 187 | 4602 | 13 | 0 | 869 | 1465 | 530 | 3125 |
|---|
| SP151 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-2];Saccharibacteria_(TM7)_[G-5];bacterium HMT356 | 8 | 6 | 0 | 0 | 0 | 0 | 205 | 163 | 29 | 22 | 4 | 101 |
|---|
| SP152 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Pseudoleptotrichia;sp. HMT219 | 87 | 0 | 26 | 15 | 201 | 0 | 30 | 15 | 24 | 93 | 20 | 38 |
|---|
| SP153 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;sp. HMT920 | 0 | 0 | 18 | 0 | 26 | 0 | 4 | 0 | 42 | 24 | 37 | 34 |
|---|
| SP154 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Butyrivibrio;sp. HMT455 | 0 | 20 | 61 | 548 | 0 | 574 | 0 | 0 | 38 | 175 | 0 | 229 |
|---|
| SP156 | Bacteria;Firmicutes;Erysipelotrichia;Erysipelotrichales;Erysipelotrichaceae;Solobacterium;moorei | 34 | 69 | 189 | 383 | 9 | 608 | 67 | 0 | 181 | 274 | 39 | 339 |
|---|
| SP157 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sp. HMT066 | 273 | 0 | 522 | 40 | 113 | 25 | 393 | 0 | 536 | 68 | 24 | 13 |
|---|
| SP158 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Bacteroidaceae;Phocaeicola;abscessus | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 85 | 0 | 10 | 0 | 0 |
|---|
| SP159 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Aggregatibacter;actinomycetemcomitans | 0 | 0 | 32 | 19 | 714 | 0 | 0 | 0 | 13 | 50 | 145 | 85 |
|---|
| SP16 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT170 | 90 | 396 | 16 | 0 | 105 | 0 | 97 | 142 | 29 | 31 | 49 | 102 |
|---|
| SP160 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sp. HMT864 | 3 | 3 | 0 | 5 | 38 | 0 | 6 | 20 | 0 | 14 | 7 | 1 |
|---|
| SP161 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;nigrescens | 0 | 170 | 84 | 0 | 144 | 40 | 387 | 1228 | 264 | 59 | 6617 | 438 |
|---|
| SP162 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptostreptococcaceae_[G-9];[Eubacterium]_brachy | 3 | 43 | 8 | 0 | 0 | 10 | 34 | 363 | 45 | 12 | 544 | 19 |
|---|
| SP163 | Bacteria;Firmicutes;Tissierellia;Tissierellales;Peptoniphilaceae;Parvimonas;sp. HMT110 | 0 | 0 | 27 | 0 | 8 | 0 | 43 | 0 | 47 | 0 | 0 | 36 |
|---|
| SP164 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;sputigena | 7 | 19 | 25 | 67 | 48 | 91 | 21 | 488 | 104 | 93 | 162 | 76 |
|---|
| SP165 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-1];bacterium HMT347 | 27 | 232 | 19 | 5 | 7 | 0 | 30 | 126 | 13 | 0 | 0 | 0 |
|---|
| SP166 | Bacteria;Actinobacteria;Actinomycetia;Micrococcales;Micrococcaceae;Rothia;mucilaginosa | 2082 | 480 | 8369 | 1507 | 3449 | 892 | 1828 | 94 | 4881 | 1030 | 293 | 560 |
|---|
| SP168 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;johnsonii | 9 | 60 | 80 | 17 | 196 | 7 | 23 | 165 | 9 | 56 | 31 | 80 |
|---|
| SP169 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT212 | 16 | 29 | 190 | 41 | 653 | 44 | 30 | 58 | 59 | 58 | 39 | 896 |
|---|
| SP17 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;graevenitzii | 215 | 1654 | 60 | 438 | 1147 | 1032 | 257 | 78 | 123 | 256 | 313 | 307 |
|---|
| SP170 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;shahii | 42 | 111 | 0 | 0 | 70 | 9 | 77 | 56 | 0 | 0 | 21 | 0 |
|---|
| SP172 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;maltophilum | 0 | 0 | 0 | 0 | 0 | 0 | 16 | 0 | 12 | 0 | 258 | 9 |
|---|
| SP173 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Schaalia;georgiae | 4 | 4 | 8 | 0 | 38 | 0 | 31 | 37 | 8 | 29 | 38 | 69 |
|---|
| SP174 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Pseudoleptotrichia;goodfellowii | 16 | 21 | 4 | 0 | 267 | 8 | 50 | 134 | 6 | 31 | 398 | 289 |
|---|
| SP175 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Kingella;sp. HMT932 | 13 | 0 | 8 | 30 | 0 | 0 | 31 | 0 | 7 | 15 | 0 | 0 |
|---|
| SP176 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;naeslundii | 67 | 254 | 146 | 0 | 103 | 44 | 191 | 199 | 91 | 10 | 12 | 332 |
|---|
| SP177 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;dentalis | 6 | 12 | 0 | 0 | 0 | 4 | 20 | 137 | 0 | 3 | 0 | 0 |
|---|
| SP179 | Bacteria;Firmicutes;Bacilli;Bacillales;Gemellaceae;Gemella;morbillorum | 70 | 12 | 179 | 56 | 131 | 23 | 69 | 0 | 159 | 63 | 1921 | 250 |
|---|
| SP18 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;sp. HMT237 | 8 | 12 | 26 | 11 | 0 | 0 | 66 | 594 | 28 | 46 | 12 | 16 |
|---|
| SP180 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;sp. HMT020 | 0 | 0 | 45 | 20 | 0 | 0 | 15 | 0 | 32 | 17 | 0 | 48 |
|---|
| SP184 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Oribacterium;sp. HMT078 | 0 | 10 | 8 | 4 | 10 | 0 | 25 | 62 | 11 | 22 | 6 | 106 |
|---|
| SP185 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;trevisanii | 22 | 29 | 0 | 20 | 0 | 21 | 141 | 434 | 0 | 77 | 91 | 274 |
|---|
| SP186 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT896 | 17 | 0 | 12 | 6 | 0 | 7 | 14 | 0 | 27 | 6 | 0 | 47 |
|---|
| SP187 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT392 | 125 | 24 | 417 | 6 | 273 | 0 | 112 | 26 | 210 | 94 | 60 | 96 |
|---|
| SP188 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lachnoanaerobaculum;gingivalis | 78 | 23 | 87 | 248 | 97 | 347 | 95 | 0 | 76 | 162 | 58 | 133 |
|---|
| SP189 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;sp. HMT204 | 34 | 0 | 29 | 0 | 68 | 0 | 72 | 211 | 20 | 107 | 26 | 180 |
|---|
| SP19 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Catonella;morbi | 37 | 49 | 975 | 590 | 31 | 112 | 59 | 40 | 228 | 294 | 83 | 285 |
|---|
| SP190 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Weeksellaceae;Weeksellaceae_[G-1];sp. HMT900 | 23 | 12 | 4 | 0 | 17 | 8 | 19 | 66 | 10 | 9 | 3 | 5 |
|---|
| SP192 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptoanaerobacter;[Eubacterium] yurii | 0 | 9 | 0 | 0 | 0 | 0 | 18 | 33 | 0 | 0 | 0 | 21 |
|---|
| SP193 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-1];bacterium HMT352 | 66 | 323 | 424 | 344 | 0 | 211 | 95 | 15 | 248 | 173 | 0 | 140 |
|---|
| SP194 | Bacteria;Absconditabacteria_(SR1);Absconditabacteria_(SR1)_[C-1];Absconditabacteria_(SR1)_[O-1];Absconditabacteria_(SR1)_[F-1];Absconditabacteria_(SR1)_[G-1];bacterium HMT875 | 0 | 0 | 9 | 161 | 0 | 11 | 0 | 0 | 5 | 74 | 0 | 4 |
|---|
| SP195 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Schaalia;sp. HMT180 | 148 | 65 | 172 | 2780 | 29 | 1225 | 132 | 91 | 405 | 1337 | 31 | 445 |
|---|
| SP196 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;baroniae | 0 | 8 | 0 | 0 | 0 | 0 | 31 | 109 | 0 | 23 | 0 | 0 |
|---|
| SP197 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT175 | 102 | 345 | 36 | 21 | 76 | 7 | 56 | 178 | 14 | 17 | 16 | 20 |
|---|
| SP198 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT301 | 0 | 0 | 0 | 0 | 8 | 0 | 4 | 33 | 0 | 0 | 0 | 43 |
|---|
| SP199 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;salivarius | 4978 | 14210 | 3087 | 7055 | 12800 | 12467 | 5547 | 1747 | 1955 | 4162 | 3144 | 6679 |
|---|
| SP2 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT215 | 79 | 0 | 123 | 496 | 55 | 337 | 171 | 0 | 158 | 301 | 103 | 197 |
|---|
| SP20 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;haemolyticus | 37 | 18 | 111 | 27 | 0 | 69 | 31 | 19 | 101 | 76 | 0 | 94 |
|---|
| SP205 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sp. HMT423 | 370 | 278 | 401 | 73 | 1740 | 60 | 325 | 695 | 247 | 79 | 590 | 325 |
|---|
| SP206 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Oribacterium;sinus | 233 | 275 | 1243 | 915 | 406 | 1155 | 207 | 31 | 202 | 332 | 114 | 764 |
|---|
| SP208 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Veillonellaceae_[G-1];bacterium HMT150 | 0 | 0 | 9 | 0 | 0 | 0 | 18 | 27 | 5 | 7 | 0 | 16 |
|---|
| SP21 | Bacteria;Proteobacteria;Epsilonproteobacteria;Campylobacterales;Campylobacteraceae;Campylobacter;gracilis | 6 | 63 | 37 | 12 | 155 | 10 | 39 | 305 | 80 | 60 | 1426 | 502 |
|---|
| SP210 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Eikenella;corrodens | 66 | 11 | 100 | 24 | 78 | 8 | 139 | 87 | 54 | 71 | 77 | 116 |
|---|
| SP211 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;oris | 33 | 24 | 0 | 0 | 215 | 0 | 6 | 32 | 0 | 0 | 72 | 0 |
|---|
| SP212 | Bacteria;Actinobacteria;Actinomycetia;Corynebacteriales;Corynebacteriaceae;Corynebacterium;durum | 312 | 457 | 99 | 31 | 89 | 26 | 283 | 181 | 57 | 36 | 23 | 59 |
|---|
| SP214 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;sp. HMT231 | 5 | 13 | 21 | 11 | 4 | 0 | 245 | 448 | 36 | 45 | 126 | 55 |
|---|
| SP215 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Aggregatibacter;sp. HMT458 | 0 | 0 | 0 | 8 | 56 | 10 | 0 | 0 | 0 | 2 | 1 | 24 |
|---|
| SP22 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;oris | 57 | 59 | 37 | 0 | 246 | 21 | 380 | 297 | 80 | 113 | 2550 | 305 |
|---|
| SP222 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sp. HMT074 | 0 | 119 | 118 | 0 | 52 | 12 | 0 | 6 | 223 | 0 | 29 | 4 |
|---|
| SP224 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;nanceiensis | 16 | 0 | 532 | 744 | 0 | 47 | 9 | 0 | 618 | 448 | 0 | 98 |
|---|
| SP225 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sp. HMT332 | 60 | 0 | 0 | 0 | 0 | 0 | 163 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP226 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-1];bacterium HMT957 | 0 | 0 | 286 | 4 | 18 | 11 | 13 | 101 | 99 | 24 | 121 | 82 |
|---|
| SP227 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Aggregatibacter;segnis | 343 | 102 | 132 | 8 | 40 | 132 | 312 | 68 | 111 | 12 | 25 | 795 |
|---|
| SP228 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;granulosa | 69 | 31 | 75 | 34 | 106 | 0 | 172 | 149 | 124 | 55 | 48 | 56 |
|---|
| SP229 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;sp. HMT914 | 17 | 0 | 254 | 632 | 0 | 38 | 27 | 0 | 279 | 318 | 0 | 80 |
|---|
| SP23 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;dentalis | 18 | 51 | 43 | 0 | 20 | 2 | 43 | 144 | 213 | 15 | 16 | 46 |
|---|
| SP230 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;periodonticum | 751 | 73 | 3004 | 5571 | 72 | 1401 | 1286 | 0 | 2317 | 3230 | 108 | 1003 |
|---|
| SP232 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;rogosae | 486 | 0 | 852 | 2563 | 0 | 0 | 415 | 0 | 820 | 1693 | 0 | 0 |
|---|
| SP233 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;mitis | 1801 | 1696 | 365 | 682 | 1520 | 274 | 1095 | 2142 | 491 | 1095 | 1225 | 300 |
|---|
| SP234 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;oralis | 870 | 362 | 320 | 80 | 1814 | 264 | 404 | 314 | 357 | 175 | 207 | 1658 |
|---|
| SP235 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;sp. HMT499 | 0 | 98 | 0 | 0 | 453 | 0 | 14 | 22 | 0 | 0 | 150 | 0 |
|---|
| SP237 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Granulicatella;elegans | 35 | 225 | 49 | 93 | 283 | 31 | 17 | 241 | 30 | 138 | 233 | 59 |
|---|
| SP238 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;sp. HMT278 | 121 | 72 | 184 | 0 | 0 | 36 | 96 | 86 | 126 | 13 | 0 | 395 |
|---|
| SP239 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sp. HMT336 | 29 | 1 | 0 | 0 | 0 | 0 | 81 | 73 | 0 | 0 | 0 | 0 |
|---|
| SP240 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;medium | 6 | 10 | 0 | 0 | 0 | 0 | 107 | 547 | 0 | 0 | 0 | 0 |
|---|
| SP241 | Bacteria;Actinobacteria;Coriobacteriia;Coriobacteriales;Atopobiaceae;Olsenella;sp. HMT807 | 5 | 12 | 8 | 0 | 71 | 0 | 121 | 361 | 24 | 41 | 15 | 150 |
|---|
| SP243 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Kingella;denitrificans | 69 | 206 | 100 | 51 | 337 | 22 | 64 | 70 | 86 | 19 | 50 | 238 |
|---|
| SP244 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sanguinis | 386 | 775 | 348 | 151 | 2109 | 402 | 221 | 369 | 203 | 134 | 246 | 1212 |
|---|
| SP245 | Bacteria;Proteobacteria;Epsilonproteobacteria;Campylobacterales;Campylobacteraceae;Campylobacter;sp. HMT044 | 9 | 0 | 15 | 43 | 0 | 0 | 10 | 0 | 0 | 13 | 0 | 0 |
|---|
| SP246 | Bacteria;Actinobacteria;Actinomycetia;Micrococcales;Micrococcaceae;Rothia;dentocariosa | 189 | 1418 | 32 | 45 | 800 | 21 | 185 | 551 | 22 | 76 | 208 | 48 |
|---|
| SP248 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Schaalia;lingnae | 14 | 74 | 65 | 97 | 45 | 65 | 7 | 0 | 43 | 83 | 0 | 21 |
|---|
| SP25 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;oralis_subsp._dentisani_clade_058 | 556 | 326 | 60 | 680 | 1838 | 104 | 473 | 256 | 50 | 631 | 178 | 201 |
|---|
| SP253 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT475 | 0 | 0 | 9 | 0 | 7 | 7 | 30 | 0 | 0 | 0 | 10 | 48 |
|---|
| SP255 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;sp. HMT308 | 83 | 37 | 8 | 27 | 17 | 483 | 94 | 0 | 0 | 13 | 7 | 246 |
|---|
| SP256 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;sp. HMT134 | 0 | 0 | 0 | 0 | 0 | 0 | 32 | 63 | 0 | 0 | 0 | 0 |
|---|
| SP258 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;mutans | 0 | 713 | 0 | 9 | 109 | 2 | 21 | 699 | 0 | 52 | 219 | 6 |
|---|
| SP259 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;flueggei | 0 | 0 | 8 | 675 | 0 | 316 | 0 | 20 | 6 | 375 | 0 | 129 |
|---|
| SP26 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;noxia | 38 | 51 | 121 | 7 | 125 | 60 | 21 | 230 | 120 | 30 | 48 | 219 |
|---|
| SP260 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;vincentii | 0 | 0 | 17 | 4 | 0 | 0 | 9 | 0 | 29 | 22 | 0 | 9 |
|---|
| SP261 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;infelix | 0 | 0 | 52 | 0 | 12 | 0 | 2 | 64 | 167 | 7 | 25 | 54 |
|---|
| SP262 | Bacteria;Actinobacteria;Coriobacteriia;Coriobacteriales;Atopobiaceae;Lancefieldella;parvula | 26 | 99 | 27 | 92 | 33 | 805 | 41 | 16 | 55 | 48 | 28 | 372 |
|---|
| SP264 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-1];bacterium HMT346 | 8 | 0 | 45 | 5 | 6 | 0 | 190 | 43 | 101 | 10 | 33 | 156 |
|---|
| SP265 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Weeksellaceae;Weeksellaceae_[G-1];sp. HMT931 | 0 | 24 | 5 | 9 | 11 | 0 | 0 | 5 | 6 | 12 | 0 | 4 |
|---|
| SP266 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT171 | 95 | 126 | 31 | 5 | 38 | 0 | 63 | 140 | 28 | 11 | 6 | 0 |
|---|
| SP268 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Anaeroglobus;geminatus | 5 | 5 | 0 | 5 | 0 | 0 | 44 | 67 | 6 | 23 | 0 | 18 |
|---|
| SP269 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Johnsonella;ignava | 14 | 0 | 3 | 2 | 17 | 4 | 74 | 163 | 16 | 21 | 113 | 134 |
|---|
| SP271 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT525 | 1 | 15 | 15 | 0 | 133 | 0 | 290 | 454 | 87 | 33 | 34 | 124 |
|---|
| SP272 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;sp. HMT036 | 0 | 23 | 51 | 157 | 356 | 0 | 4 | 9 | 0 | 188 | 88 | 0 |
|---|
| SP273 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Veillonellaceae_[G-1];bacterium HMT132 | 0 | 0 | 0 | 0 | 0 | 0 | 53 | 46 | 0 | 0 | 0 | 0 |
|---|
| SP276 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;sp. HMT284 | 12 | 6 | 0 | 0 | 122 | 14 | 34 | 49 | 0 | 5 | 20 | 319 |
|---|
| SP277 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;dianae | 0 | 0 | 24 | 0 | 5 | 0 | 0 | 45 | 51 | 0 | 36 | 44 |
|---|
| SP278 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;oralis_subsp._tigurinus_clade_071 | 21 | 86 | 0 | 0 | 0 | 0 | 9 | 133 | 0 | 0 | 0 | 0 |
|---|
| SP279 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT225 | 85 | 25 | 0 | 27 | 0 | 0 | 38 | 40 | 0 | 19 | 0 | 0 |
|---|
| SP28 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT169 | 10 | 75 | 18 | 17 | 56 | 5 | 9 | 76 | 16 | 33 | 4 | 0 |
|---|
| SP280 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Aggregatibacter;aphrophilus | 0 | 0 | 336 | 0 | 0 | 6 | 74 | 0 | 110 | 0 | 0 | 39 |
|---|
| SP281 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;wadei | 17 | 518 | 73 | 0 | 487 | 91 | 41 | 2407 | 109 | 0 | 114 | 143 |
|---|
| SP284 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;canifelinum | 8 | 0 | 0 | 0 | 0 | 0 | 132 | 22 | 0 | 0 | 0 | 0 |
|---|
| SP285 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;australis | 0 | 107 | 737 | 2349 | 0 | 0 | 0 | 41 | 915 | 1711 | 0 | 0 |
|---|
| SP287 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;micans | 0 | 0 | 15 | 0 | 22 | 25 | 0 | 21 | 11 | 8 | 15 | 262 |
|---|
| SP289 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;sp. HMT018 | 83 | 13 | 0 | 0 | 0 | 0 | 197 | 13 | 0 | 0 | 0 | 0 |
|---|
| SP29 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lachnoanaerobaculum;saburreum | 15 | 40 | 13 | 0 | 68 | 0 | 48 | 148 | 0 | 0 | 22 | 75 |
|---|
| SP290 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;anginosus | 36 | 51 | 9 | 0 | 0 | 0 | 29 | 70 | 19 | 0 | 0 | 4 |
|---|
| SP292 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sp. HMT338 | 0 | 6 | 0 | 0 | 13 | 0 | 14 | 94 | 5 | 13 | 22 | 253 |
|---|
| SP293 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;cristatus | 280 | 0 | 0 | 2 | 0 | 0 | 123 | 0 | 0 | 4 | 0 | 0 |
|---|
| SP297 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;oralis | 748 | 528 | 327 | 146 | 1992 | 326 | 378 | 361 | 87 | 98 | 97 | 235 |
|---|
| SP299 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;ochracea | 0 | 0 | 6 | 0 | 31 | 0 | 0 | 56 | 25 | 107 | 17 | 104 |
|---|
| SP30 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Granulicatella;adiacens | 543 | 657 | 1317 | 1003 | 970 | 451 | 663 | 225 | 1739 | 791 | 600 | 626 |
|---|
| SP301 | Bacteria;Firmicutes;Tissierellia;Tissierellales;Peptoniphilaceae;Parvimonas;micra | 28 | 157 | 32 | 0 | 26 | 10 | 33 | 709 | 67 | 37 | 3714 | 13 |
|---|
| SP302 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;intermedius | 15 | 98 | 47 | 0 | 55 | 0 | 113 | 150 | 119 | 53 | 3223 | 121 |
|---|
| SP308 | Bacteria;Actinobacteria;Actinomycetia;Bifidobacteriales;Bifidobacteriaceae;Scardovia;wiggsiae | 0 | 20 | 0 | 0 | 24 | 0 | 0 | 28 | 0 | 3 | 19 | 2 |
|---|
| SP309 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;hwasookii | 0 | 0 | 394 | 0 | 77 | 0 | 0 | 0 | 42 | 0 | 0 | 44 |
|---|
| SP310 | Bacteria;Absconditabacteria_(SR1);Absconditabacteria_(SR1)_[C-1];Absconditabacteria_(SR1)_[O-1];Absconditabacteria_(SR1)_[F-1];Absconditabacteria_(SR1)_[G-1];bacterium HMT874 | 8 | 3 | 131 | 142 | 9 | 7 | 8 | 0 | 43 | 93 | 3 | 0 |
|---|
| SP314 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;koreensis | 7 | 3 | 0 | 44 | 0 | 43 | 42 | 54 | 0 | 134 | 0 | 0 |
|---|
| SP315 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;hongkongensis | 189 | 578 | 26 | 11 | 2079 | 0 | 186 | 230 | 9 | 13 | 114 | 0 |
|---|
| SP317 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-1];bacterium HMT869 | 5 | 7 | 0 | 0 | 37 | 6 | 4 | 62 | 0 | 0 | 17 | 327 |
|---|
| SP318 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Schaalia;sp. HMT172 | 1051 | 2391 | 0 | 0 | 0 | 0 | 977 | 164 | 0 | 0 | 0 | 0 |
|---|
| SP319 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Peptidiphaga;sp. HMT183 | 3 | 224 | 8 | 14 | 134 | 11 | 49 | 866 | 87 | 68 | 52 | 93 |
|---|
| SP320 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;sp. HMT258 | 0 | 0 | 0 | 0 | 0 | 0 | 32 | 88 | 0 | 0 | 0 | 0 |
|---|
| SP321 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;sputorum | 0 | 0 | 154 | 0 | 9 | 36 | 0 | 0 | 68 | 0 | 7 | 34 |
|---|
| SP322 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;sp. HMT930 | 8 | 0 | 0 | 199 | 80 | 33 | 0 | 0 | 0 | 75 | 34 | 61 |
|---|
| SP325 | Bacteria;Actinobacteria;Coriobacteriia;Coriobacteriales;Atopobiaceae;Olsenella;profusa | 0 | 46 | 0 | 0 | 0 | 0 | 0 | 644 | 0 | 11 | 0 | 0 |
|---|
| SP328 | Bacteria;Proteobacteria;Gammaproteobacteria;Cardiobacteriales;Cardiobacteriaceae;Cardiobacterium;hominis | 71 | 31 | 30 | 14 | 93 | 7 | 81 | 73 | 11 | 18 | 11 | 45 |
|---|
| SP33 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;pittmaniae | 119 | 0 | 0 | 0 | 0 | 0 | 250 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP330 | Bacteria;Actinobacteria;Actinomycetia;Propionibacteriales;Propionibacteriaceae;Propionibacterium;acidifaciens | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 156 | 0 | 0 |
|---|
| SP339 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;sp. HMT479 | 0 | 2 | 0 | 0 | 11 | 0 | 0 | 0 | 22 | 9 | 17 | 22 |
|---|
| SP34 | Bacteria;Synergistetes;Synergistia;Synergistales;Synergistaceae;Fretibacterium;sp. HMT360 | 0 | 0 | 0 | 3 | 0 | 0 | 118 | 161 | 9 | 49 | 53 | 8 |
|---|
| SP342 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;catoniae | 30 | 0 | 117 | 27 | 35 | 30 | 45 | 0 | 66 | 52 | 0 | 254 |
|---|
| SP343 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;lecithinolyticum | 14 | 8 | 20 | 6 | 11 | 0 | 76 | 99 | 7 | 14 | 155 | 13 |
|---|
| SP345 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;sp. HMT262 | 17 | 13 | 0 | 0 | 0 | 0 | 108 | 145 | 0 | 0 | 0 | 0 |
|---|
| SP347 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptostreptococcaceae_[G-7];[Eubacterium]_yurii_subsps._yurii_&_margaretiae | 16 | 0 | 23 | 8 | 16 | 10 | 13 | 0 | 30 | 57 | 3 | 94 |
|---|
| SP348 | Bacteria;Synergistetes;Synergistia;Synergistales;Synergistaceae;Fretibacterium;sp. HMT359 | 0 | 6 | 0 | 0 | 0 | 0 | 14 | 83 | 0 | 0 | 0 | 0 |
|---|
| SP349 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;parahaemolyticus | 764 | 296 | 4 | 7 | 8 | 0 | 733 | 220 | 4 | 4 | 161 | 0 |
|---|
| SP350 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Tannerellaceae;Tannerella;forsythia | 18 | 13 | 13 | 13 | 9 | 6 | 97 | 230 | 9 | 67 | 305 | 4 |
|---|
| SP352 | Bacteria;Proteobacteria;Epsilonproteobacteria;Campylobacterales;Campylobacteraceae;Campylobacter;showae | 58 | 15 | 333 | 512 | 76 | 191 | 84 | 36 | 245 | 260 | 20 | 229 |
|---|
| SP354 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;gingivalis | 0 | 0 | 65 | 74 | 0 | 44 | 0 | 0 | 34 | 361 | 0 | 21 |
|---|
| SP356 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Peptidiphaga;gingivicola | 17 | 154 | 7 | 8 | 279 | 0 | 13 | 202 | 11 | 14 | 53 | 0 |
|---|
| SP357 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;sicca | 468 | 1084 | 728 | 213 | 6594 | 1265 | 376 | 696 | 346 | 172 | 335 | 1644 |
|---|
| SP358 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;chosunense | 1150 | 2368 | 94 | 83 | 200 | 29 | 818 | 2123 | 62 | 171 | 45 | 39 |
|---|
| SP36 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptostreptococcaceae_[G-1];[Eubacterium]_sulci | 4 | 16 | 9 | 80 | 0 | 36 | 7 | 0 | 11 | 73 | 0 | 23 |
|---|
| SP360 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;flava | 393 | 0 | 0 | 0 | 0 | 0 | 366 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP363 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT304 | 0 | 5 | 0 | 80 | 0 | 0 | 0 | 56 | 0 | 151 | 0 | 0 |
|---|
| SP364 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Tannerellaceae;Tannerella;serpentiformis | 0 | 0 | 25 | 28 | 56 | 0 | 17 | 0 | 20 | 23 | 0 | 55 |
|---|
| SP367 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT463 | 0 | 0 | 339 | 0 | 0 | 0 | 0 | 0 | 122 | 0 | 0 | 74 |
|---|
| SP368 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;artemidis | 0 | 0 | 38 | 0 | 27 | 8 | 0 | 11 | 45 | 8 | 11 | 141 |
|---|
| SP369 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-1];bacterium HMT349 | 0 | 6 | 9 | 0 | 0 | 0 | 40 | 53 | 30 | 24 | 0 | 0 |
|---|
| SP37 | Bacteria;Proteobacteria;Gammaproteobacteria;Cardiobacteriales;Cardiobacteriaceae;Cardiobacterium;valvarum | 26 | 26 | 26 | 9 | 183 | 12 | 46 | 107 | 31 | 69 | 119 | 113 |
|---|
| SP370 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Tannerellaceae;Tannerella;sp. HMT808 | 0 | 6 | 0 | 4 | 62 | 0 | 26 | 118 | 0 | 32 | 18 | 86 |
|---|
| SP373 | Bacteria;Actinobacteria;Coriobacteriia;Coriobacteriales;Atopobiaceae;Olsenella;uli | 0 | 5 | 0 | 0 | 0 | 0 | 22 | 79 | 0 | 5 | 0 | 0 |
|---|
| SP379 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;massiliensis | 72 | 94 | 46 | 31 | 194 | 14 | 38 | 123 | 43 | 74 | 15 | 100 |
|---|
| SP38 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;hofstadii | 13 | 195 | 85 | 23 | 129 | 22 | 0 | 346 | 22 | 39 | 18 | 215 |
|---|
| SP380 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Schaalia;sp. HMT877 | 19 | 17 | 24 | 0 | 49 | 9 | 15 | 142 | 18 | 10 | 31 | 182 |
|---|
| SP381 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sp. HMT056 | 59 | 5 | 37 | 7 | 0 | 0 | 70 | 0 | 22 | 7 | 0 | 3 |
|---|
| SP384 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;perflava | 0 | 0 | 1875 | 12762 | 1755 | 1752 | 0 | 0 | 2115 | 7758 | 513 | 1729 |
|---|
| SP387 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;cinerea | 5 | 0 | 0 | 59 | 0 | 0 | 8 | 0 | 0 | 67 | 85 | 0 |
|---|
| SP39 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sp. HMT323 | 0 | 0 | 0 | 0 | 70 | 22 | 0 | 79 | 0 | 0 | 48 | 149 |
|---|
| SP395 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Eubacteriaceae;Pseudoramibacter;alactolyticus | 0 | 46 | 0 | 0 | 0 | 0 | 13 | 45 | 0 | 0 | 0 | 0 |
|---|
| SP396 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptostreptococcaceae_[G-6];[Eubacterium]_nodatum | 0 | 11 | 0 | 0 | 0 | 3 | 0 | 85 | 3 | 6 | 2 | 0 |
|---|
| SP397 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;oralis | 0 | 14 | 0 | 3 | 0 | 0 | 72 | 63 | 8 | 25 | 73 | 3 |
|---|
| SP399 | Bacteria;Bacteroidetes;Bacteroidetes_[C-1];Bacteroidetes_[O-1];Bacteroidetes_[F-1];Bacteroidetes_[G-5];bacterium HMT511 | 6 | 5 | 8 | 8 | 0 | 0 | 22 | 40 | 5 | 19 | 0 | 0 |
|---|
| SP4 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sp. HMT064 | 159 | 228 | 0 | 1229 | 0 | 99 | 178 | 973 | 0 | 1026 | 0 | 46 |
|---|
| SP401 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT223 | 0 | 8 | 0 | 0 | 183 | 0 | 23 | 83 | 0 | 14 | 18 | 116 |
|---|
| SP402 | Bacteria;Absconditabacteria_(SR1);Absconditabacteria_(SR1)_[C-1];Absconditabacteria_(SR1)_[O-1];Absconditabacteria_(SR1)_[F-1];Absconditabacteria_(SR1)_[G-1];bacterium HMT345 | 0 | 0 | 24 | 229 | 0 | 14 | 5 | 5 | 8 | 113 | 0 | 44 |
|---|
| SP403 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptococcaceae;Peptococcus;sp. HMT168 | 4 | 0 | 58 | 76 | 0 | 47 | 12 | 0 | 65 | 47 | 0 | 29 |
|---|
| SP404 | Bacteria;Actinobacteria;Coriobacteriia;Coriobacteriales;Atopobiaceae;Lancefieldella;rimae | 0 | 10 | 0 | 9 | 21 | 0 | 6 | 35 | 7 | 12 | 8 | 0 |
|---|
| SP408 | Bacteria;Actinobacteria;Actinomycetia;Propionibacteriales;Propionibacteriaceae;Propionibacteriaceae_[G-1];bacterium HMT915 | 0 | 0 | 0 | 33 | 0 | 0 | 0 | 0 | 3 | 173 | 0 | 17 |
|---|
| SP410 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT448 | 0 | 250 | 0 | 4 | 226 | 23 | 42 | 339 | 24 | 56 | 71 | 245 |
|---|
| SP412 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-1];bacterium HMT348 | 17 | 30 | 96 | 0 | 45 | 38 | 10 | 203 | 50 | 10 | 7 | 263 |
|---|
| SP417 | Bacteria;Gracilibacteria_(GN02);Gracilibacteria_(GN02)_[C-1];Gracilibacteria_(GN02)_[O-1];Gracilibacteria_(GN02)_[F-1];Gracilibacteria_(GN02)_[G-1];bacterium HMT872 | 34 | 9 | 114 | 14 | 338 | 21 | 12 | 16 | 27 | 24 | 40 | 85 |
|---|
| SP42 | Bacteria;Proteobacteria;Betaproteobacteria;Burkholderiales;Comamonadaceae;Ottowia;sp. HMT894 | 30 | 7 | 223 | 23 | 17 | 41 | 94 | 9 | 289 | 279 | 14 | 100 |
|---|
| SP420 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Ruminococcaceae;Ruminococcaceae_[G-2];bacterium HMT085 | 17 | 26 | 43 | 95 | 0 | 86 | 33 | 6 | 20 | 46 | 0 | 122 |
|---|
| SP421 | Bacteria;Tenericutes;Mollicutes;Mycoplasmatales;Mycoplasmataceae;Mycoplasma;salivarium | 0 | 0 | 0 | 0 | 9 | 3 | 0 | 5 | 0 | 8 | 89 | 0 |
|---|
| SP422 | Bacteria;Tenericutes;Mollicutes;Mycoplasmatales;Mycoplasmataceae;Mycoplasma;faucium | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 68 | 0 | 0 | 0 | 0 |
|---|
| SP43 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;oralis_subsp._tigurinus_clade_070 | 17 | 0 | 165 | 98 | 0 | 0 | 52 | 0 | 249 | 84 | 0 | 0 |
|---|
| SP430 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Weeksellaceae;Cloacibacterium;sp. HMT206 | 310 | 62 | 0 | 0 | 0 | 0 | 365 | 19 | 0 | 0 | 0 | 0 |
|---|
| SP44 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT498 | 8 | 103 | 16 | 0 | 0 | 0 | 0 | 834 | 15 | 0 | 0 | 0 |
|---|
| SP45 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;pleuritidis | 116 | 44 | 103 | 7 | 47 | 31 | 337 | 160 | 56 | 41 | 2829 | 5 |
|---|
| SP46 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sputigena | 142 | 87 | 202 | 57 | 902 | 57 | 110 | 145 | 37 | 109 | 113 | 694 |
|---|
| SP47 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;endodontalis | 80 | 83 | 52 | 57 | 45 | 47 | 286 | 657 | 56 | 56 | 1818 | 12 |
|---|
| SP48 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;salivae | 71 | 261 | 48 | 357 | 21 | 555 | 98 | 171 | 23 | 133 | 9 | 281 |
|---|
| SP49 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-3];bacterium HMT351 | 61 | 24 | 201 | 155 | 19 | 112 | 45 | 24 | 86 | 95 | 6 | 150 |
|---|
| SP5 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Veillonellaceae_[G-1];bacterium HMT155 | 0 | 7 | 0 | 0 | 19 | 0 | 16 | 104 | 7 | 10 | 16 | 14 |
|---|
| SP50 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;israelii | 0 | 16 | 0 | 0 | 0 | 0 | 0 | 115 | 35 | 11 | 0 | 9 |
|---|
| SP51 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;rava | 12 | 6 | 0 | 10 | 0 | 14 | 25 | 13 | 3 | 17 | 27 | 29 |
|---|
| SP52 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;nucleatum_subsp._animalis | 0 | 126 | 33 | 40 | 419 | 39 | 80 | 558 | 124 | 172 | 467 | 1729 |
|---|
| SP55 | Bacteria;Actinobacteria;Actinomycetia;Propionibacteriales;Propionibacteriaceae;Acidipropionibacterium;acidifaciens | 0 | 39 | 0 | 0 | 0 | 0 | 0 | 66 | 0 | 0 | 0 | 0 |
|---|
| SP56 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;atypica | 321 | 1891 | 63 | 1394 | 345 | 3788 | 503 | 108 | 64 | 718 | 462 | 2316 |
|---|
| SP57 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;maculosa | 6 | 22 | 8 | 0 | 115 | 11 | 22 | 258 | 24 | 41 | 44 | 501 |
|---|
| SP58 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;nucleatum_subsp._vincentii | 12 | 104 | 111 | 96 | 252 | 45 | 98 | 730 | 125 | 350 | 4131 | 902 |
|---|
| SP6 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lachnoanaerobaculum;orale | 0 | 183 | 119 | 228 | 0 | 0 | 0 | 13 | 129 | 170 | 0 | 0 |
|---|
| SP60 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;buccae | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 43 | 18 | 15 | 0 | 0 |
|---|
| SP61 | Bacteria;Firmicutes;Bacilli;Bacillales;Gemellaceae;Gemella;haemolysans | 898 | 798 | 281 | 120 | 299 | 34 | 697 | 602 | 384 | 235 | 356 | 33 |
|---|
| SP62 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT317 | 50 | 23 | 41 | 0 | 122 | 21 | 93 | 114 | 268 | 0 | 64 | 782 |
|---|
| SP63 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;sp. HMT473 | 97 | 34 | 787 | 616 | 0 | 0 | 46 | 251 | 469 | 374 | 817 | 0 |
|---|
| SP66 | Bacteria;Firmicutes;Bacilli;Bacillales;Gemellaceae;Gemella;sanguinis | 484 | 279 | 412 | 815 | 232 | 51 | 362 | 36 | 568 | 696 | 58 | 45 |
|---|
| SP67 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;denticola | 12 | 42 | 0 | 53 | 252 | 8 | 0 | 168 | 7 | 147 | 44 | 126 |
|---|
| SP68 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lachnoanaerobaculum;umeaense | 0 | 16 | 578 | 676 | 57 | 0 | 0 | 26 | 354 | 335 | 0 | 60 |
|---|
| SP69 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;oulorum | 3 | 28 | 9 | 157 | 100 | 103 | 11 | 155 | 15 | 55 | 127 | 364 |
|---|
| SP7 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT472 | 27 | 19 | 18 | 28 | 90 | 24 | 30 | 228 | 11 | 133 | 39 | 577 |
|---|
| SP70 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lachnospiraceae_[G-2];bacterium HMT096 | 87 | 277 | 0 | 0 | 0 | 0 | 496 | 7 | 0 | 0 | 0 | 0 |
|---|
| SP71 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;pallens | 154 | 397 | 716 | 1294 | 5 | 968 | 253 | 5 | 467 | 633 | 3 | 515 |
|---|
| SP72 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Filifactor;alocis | 8 | 26 | 8 | 21 | 6 | 15 | 72 | 203 | 19 | 46 | 267 | 5 |
|---|
| SP73 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;tannerae | 38 | 96 | 60 | 79 | 60 | 20 | 198 | 1285 | 139 | 200 | 144 | 382 |
|---|
| SP74 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;socranskii | 4 | 13 | 3 | 0 | 18 | 0 | 105 | 279 | 19 | 32 | 71 | 100 |
|---|
| SP75 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;cristatus_clade_578 | 607 | 1737 | 80 | 84 | 1022 | 81 | 478 | 966 | 85 | 103 | 119 | 229 |
|---|
| SP76 | Bacteria;Actinobacteria;Actinomycetia;Corynebacteriales;Corynebacteriaceae;Corynebacterium;matruchotii | 159 | 68 | 98 | 0 | 482 | 37 | 712 | 465 | 180 | 38 | 176 | 878 |
|---|
| SP77 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;fusca | 17 | 0 | 0 | 0 | 0 | 0 | 143 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP79 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Stomatobaculum;sp. HMT097 | 91 | 0 | 8 | 107 | 36 | 43 | 213 | 9 | 16 | 60 | 19 | 11 |
|---|
| SP8 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;nucleatum | 190 | 155 | 924 | 88 | 1098 | 219 | 657 | 1530 | 582 | 277 | 12900 | 2215 |
|---|
| SP80 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Dialister;invisus | 10 | 30 | 14 | 7 | 151 | 0 | 167 | 181 | 86 | 61 | 147 | 241 |
|---|
| SP81 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;jejuni | 130 | 797 | 0 | 0 | 0 | 0 | 375 | 29 | 0 | 0 | 0 | 0 |
|---|
| SP82 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;paraphrohaemolyticus | 562 | 7 | 0 | 0 | 0 | 0 | 588 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP83 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;parainfluenzae | 1034 | 859 | 2472 | 2599 | 1367 | 294 | 1857 | 229 | 2113 | 1773 | 600 | 381 |
|---|
| SP84 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;parasanguinis_clade_411 | 1075 | 3126 | 0 | 0 | 1026 | 505 | 1171 | 508 | 14 | 0 | 340 | 353 |
|---|
| SP85 | Bacteria;Proteobacteria;Epsilonproteobacteria;Campylobacterales;Campylobacteraceae;Campylobacter;concisus | 78 | 312 | 981 | 895 | 359 | 1353 | 275 | 41 | 301 | 277 | 211 | 1070 |
|---|
| SP86 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;melaninogenica | 885 | 1226 | 1325 | 1999 | 341 | 5013 | 1552 | 120 | 1101 | 1005 | 204 | 2626 |
|---|
| SP87 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Bacteroidales_[F-2];Bacteroidales_[G-2];bacterium HMT274 | 55 | 6 | 49 | 334 | 0 | 10 | 225 | 115 | 77 | 204 | 31 | 85 |
|---|
| SP88 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;koreensis | 0 | 0 | 895 | 155 | 0 | 0 | 0 | 0 | 913 | 143 | 0 | 0 |
|---|
| SP89 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sp. HMT057 | 0 | 52 | 17 | 0 | 0 | 30 | 0 | 0 | 9 | 0 | 0 | 15 |
|---|
| SP9 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptococcaceae;Peptococcus;sp. HMT167 | 6 | 4 | 2 | 0 | 32 | 0 | 37 | 64 | 6 | 25 | 379 | 89 |
|---|
| SP90 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;elongata | 120 | 55 | 351 | 50 | 111 | 29 | 170 | 46 | 217 | 32 | 17 | 362 |
|---|
| SP92 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Neisseria;subflava | 208 | 2708 | 4193 | 147 | 501 | 268 | 252 | 488 | 3779 | 164 | 104 | 1423 |
|---|
| SP93 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT315 | 0 | 0 | 3 | 6 | 0 | 6 | 0 | 48 | 4 | 5 | 0 | 4 |
|---|
| SP95 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Johnsonella;sp. HMT166 | 2 | 9 | 0 | 0 | 0 | 0 | 35 | 229 | 0 | 0 | 0 | 0 |
|---|
| SP97 | Bacteria;Saccharibacteria_(TM7);Saccharibacteria_(TM7)_[C-1];Saccharibacteria_(TM7)_[O-1];Saccharibacteria_(TM7)_[F-1];Saccharibacteria_(TM7)_[G-6];bacterium HMT870 | 76 | 327 | 69 | 70 | 0 | 0 | 55 | 34 | 26 | 58 | 0 | 0 |
|---|
| SP98 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;periodonticum | 0 | 0 | 76 | 273 | 428 | 384 | 0 | 0 | 70 | 251 | 141 | 239 |
|---|
| SP99 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;infantis_clade_431 | 374 | 53 | 224 | 83 | 136 | 0 | 357 | 0 | 208 | 70 | 32 | 0 |
|---|
| SPN104 | Bacteria;Actinobacteria;Actinomycetia;Corynebacteriales;Corynebacteriaceae;Corynebacterium;matruchotii_nov_97.951% | 0 | 1084 | 0 | 0 | 0 | 0 | 0 | 1578 | 0 | 0 | 0 | 0 |
|---|
| SPN106 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;sp. HMT927 nov_91.411% | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 403 | 7 | 20 | 0 | 2 |
|---|
| SPN115 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptostreptococcaceae_[G-5];bacterium HMT493 nov_96.458% | 5 | 0 | 189 | 200 | 0 | 0 | 0 | 0 | 29 | 100 | 0 | 0 |
|---|
| SPN127 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;sp. HMT305 nov_93.865% | 13 | 0 | 79 | 83 | 0 | 40 | 29 | 0 | 66 | 33 | 0 | 27 |
|---|
| SPN139 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT225 nov_96.304% | 0 | 29 | 0 | 0 | 0 | 0 | 0 | 265 | 0 | 0 | 0 | 0 |
|---|
| SPN148 | Bacteria;Proteobacteria;Betaproteobacteria;Neisseriales;Neisseriaceae;Kingella;oralis_nov_97.536% | 85 | 19 | 0 | 0 | 10 | 0 | 122 | 41 | 0 | 0 | 0 | 5 |
|---|
| SPN15 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Peptidiphaga;gingivicola_nov_94.057% | 0 | 84 | 0 | 0 | 29 | 5 | 0 | 49 | 0 | 10 | 4 | 7 |
|---|
| SPN156 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT175 nov_97.746% | 0 | 0 | 29 | 10 | 102 | 18 | 0 | 0 | 17 | 9 | 0 | 51 |
|---|
| SPN166 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lacrimispora;xylanolytica_nov_88.866% | 5 | 0 | 77 | 6 | 8 | 3 | 4 | 0 | 51 | 22 | 0 | 60 |
|---|
| SPN175 | Bacteria;Spirochaetes;Spirochaetia;Spirochaetales;Treponemataceae;Treponema;sp. HMT237 nov_97.972% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 210 | 0 | 0 | 0 | 0 |
|---|
| SPN185 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Leptotrichiaceae;Leptotrichia;sp. HMT417 nov_97.826% | 0 | 0 | 23 | 1400 | 0 | 160 | 0 | 0 | 13 | 550 | 0 | 68 |
|---|
| SPN186 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;gingivalis_nov_96.218% | 33 | 0 | 29 | 9 | 0 | 5 | 52 | 0 | 10 | 19 | 0 | 43 |
|---|
| SPN25 | Bacteria;Firmicutes;Negativicutes;Selenomonadales;Selenomonadaceae;Selenomonas;artemidis_nov_97.628% | 0 | 0 | 32 | 0 | 13 | 5 | 0 | 0 | 37 | 6 | 9 | 79 |
|---|
| SPN28 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;gingivalis_nov_90.546% | 28 | 4 | 63 | 9 | 0 | 0 | 13 | 0 | 12 | 19 | 0 | 0 |
|---|
| SPN29 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;catoniae_nov_97.746% | 51 | 43 | 0 | 0 | 0 | 0 | 29 | 13 | 0 | 0 | 0 | 0 |
|---|
| SPN30 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;catoniae_nov_97.751% | 42 | 0 | 0 | 0 | 0 | 0 | 79 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPN31 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Aggregatibacter;aphrophilus_nov_97.551% | 42 | 24 | 0 | 0 | 0 | 0 | 25 | 29 | 0 | 0 | 0 | 0 |
|---|
| SPN32 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Peptostreptococcaceae;Peptostreptococcaceae_[G-2];bacterium HMT091 nov_97.286% | 0 | 0 | 23 | 35 | 0 | 0 | 0 | 0 | 0 | 28 | 0 | 0 |
|---|
| SPN33 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;gingivalis_nov_97.689% | 10 | 5 | 166 | 32 | 99 | 0 | 20 | 11 | 68 | 49 | 19 | 32 |
|---|
| SPN34 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;viscosus_nov_97.955% | 13 | 0 | 0 | 0 | 0 | 0 | 70 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPN35 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT171 nov_96.813% | 0 | 72 | 242 | 0 | 249 | 0 | 0 | 212 | 109 | 17 | 103 | 392 |
|---|
| SPN36 | Bacteria;Proteobacteria;Gammaproteobacteria;Cardiobacteriales;Cardiobacteriaceae;Cardiobacterium;hominis_nov_97.718% | 29 | 8 | 0 | 0 | 0 | 0 | 35 | 8 | 0 | 0 | 0 | 0 |
|---|
| SPN47 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Peptidiphaga;gingivicola_nov_96.920% | 50 | 49 | 25 | 9 | 183 | 28 | 95 | 332 | 12 | 36 | 26 | 443 |
|---|
| SPN5 | Bacteria;Actinobacteria;Actinomycetia;Corynebacteriales;Corynebacteriaceae;Corynebacterium;matruchotii_nov_97.358% | 0 | 0 | 0 | 24 | 0 | 0 | 0 | 0 | 63 | 104 | 0 | 0 |
|---|
| SPN58 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;sp. HMT473 nov_97.751% | 13 | 0 | 176 | 488 | 5 | 135 | 0 | 0 | 192 | 207 | 0 | 69 |
|---|
| SPN68 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;sp. HMT308 nov_91.411% | 0 | 0 | 30 | 621 | 0 | 242 | 0 | 0 | 24 | 199 | 0 | 134 |
|---|
| SPN78 | Bacteria;Actinobacteria;Actinomycetia;Actinomycetales;Actinomycetaceae;Actinomyces;sp. HMT175 nov_97.963% | 0 | 467 | 0 | 0 | 0 | 0 | 0 | 268 | 0 | 0 | 0 | 0 |
|---|
| SPN88 | Bacteria;Actinobacteria;Actinomycetia;Corynebacteriales;Corynebacteriaceae;Corynebacterium;durum_nov_97.484% | 56 | 341 | 14 | 5 | 57 | 10 | 47 | 112 | 11 | 14 | 9 | 26 |
|---|
| SPN97 | Bacteria;Firmicutes;Tissierellia;Tissierellales;Peptoniphilaceae;Parvimonas;sp. HMT393 nov_97.053% | 0 | 0 | 133 | 249 | 0 | 0 | 0 | 0 | 147 | 170 | 0 | 0 |
|---|
| SPP11 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Lachnoanaerobaculum;multispecies_spp11_2 | 20 | 0 | 4 | 0 | 28 | 97 | 7 | 0 | 0 | 0 | 16 | 44 |
|---|
| SPP13 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;multispecies_spp13_2 | 0 | 0 | 13 | 11 | 34 | 12 | 0 | 0 | 19 | 70 | 22 | 127 |
|---|
| SPP14 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;multispecies_spp14_3 | 0 | 0 | 0 | 0 | 145 | 8 | 0 | 0 | 0 | 0 | 4215 | 0 |
|---|
| SPP15 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;multispecies_spp15_2 | 572 | 1011 | 0 | 5 | 122 | 623 | 959 | 55 | 0 | 6 | 112 | 242 |
|---|
| SPP16 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Porphyromonadaceae;Porphyromonas;multispecies_spp16_2 | 48 | 23 | 0 | 0 | 0 | 0 | 85 | 99 | 0 | 0 | 0 | 0 |
|---|
| SPP20 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;multispecies_spp20_2 | 786 | 32 | 1257 | 420 | 38 | 38 | 1867 | 0 | 1853 | 328 | 12 | 20 |
|---|
| SPP21 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;multispecies_spp21_3 | 0 | 0 | 19 | 75 | 0 | 0 | 0 | 0 | 20 | 80 | 0 | 0 |
|---|
| SPP22 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;multispecies_spp22_3 | 8 | 5 | 1298 | 182 | 0 | 0 | 0 | 0 | 1338 | 183 | 0 | 0 |
|---|
| SPP25 | Bacteria;Fusobacteria;Fusobacteriia;Fusobacteriales;Fusobacteriaceae;Fusobacterium;multispecies_spp25_2 | 0 | 50 | 0 | 0 | 61 | 0 | 63 | 367 | 12 | 86 | 92 | 510 |
|---|
| SPP3 | Bacteria;Firmicutes;Clostridia;Eubacteriales;Lachnospiraceae;Oribacterium;multispecies_spp3_2 | 42 | 77 | 652 | 520 | 246 | 306 | 42 | 16 | 197 | 259 | 49 | 155 |
|---|
| SPP5 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;multispecies_spp5_2 | 0 | 2 | 0 | 18 | 62 | 0 | 10 | 0 | 0 | 53 | 7 | 19 |
|---|
| SPP7 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Tannerellaceae;Tannerella;multispecies_spp7_2 | 0 | 10 | 0 | 23 | 0 | 0 | 0 | 45 | 0 | 0 | 0 | 49 |
|---|
| SPP8 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;multispecies_spp8_2 | 276 | 1849 | 126 | 49 | 934 | 180 | 381 | 1578 | 167 | 186 | 569 | 1443 |
|---|
| SPP9 | Bacteria;Firmicutes;Negativicutes;Veillonellales;Veillonellaceae;Veillonella;multispecies_spp9_3 | 14 | 0 | 307 | 37 | 466 | 169 | 15 | 0 | 374 | 23 | 242 | 134 |
|---|
| SPPN9 | Bacteria;Proteobacteria;Gammaproteobacteria;Pasteurellales;Pasteurellaceae;Haemophilus;multispecies_sppn9_2_nov_97.536% | 144 | 126 | 0 | 0 | 0 | 0 | 109 | 55 | 0 | 0 | 0 | 0 |
|---|

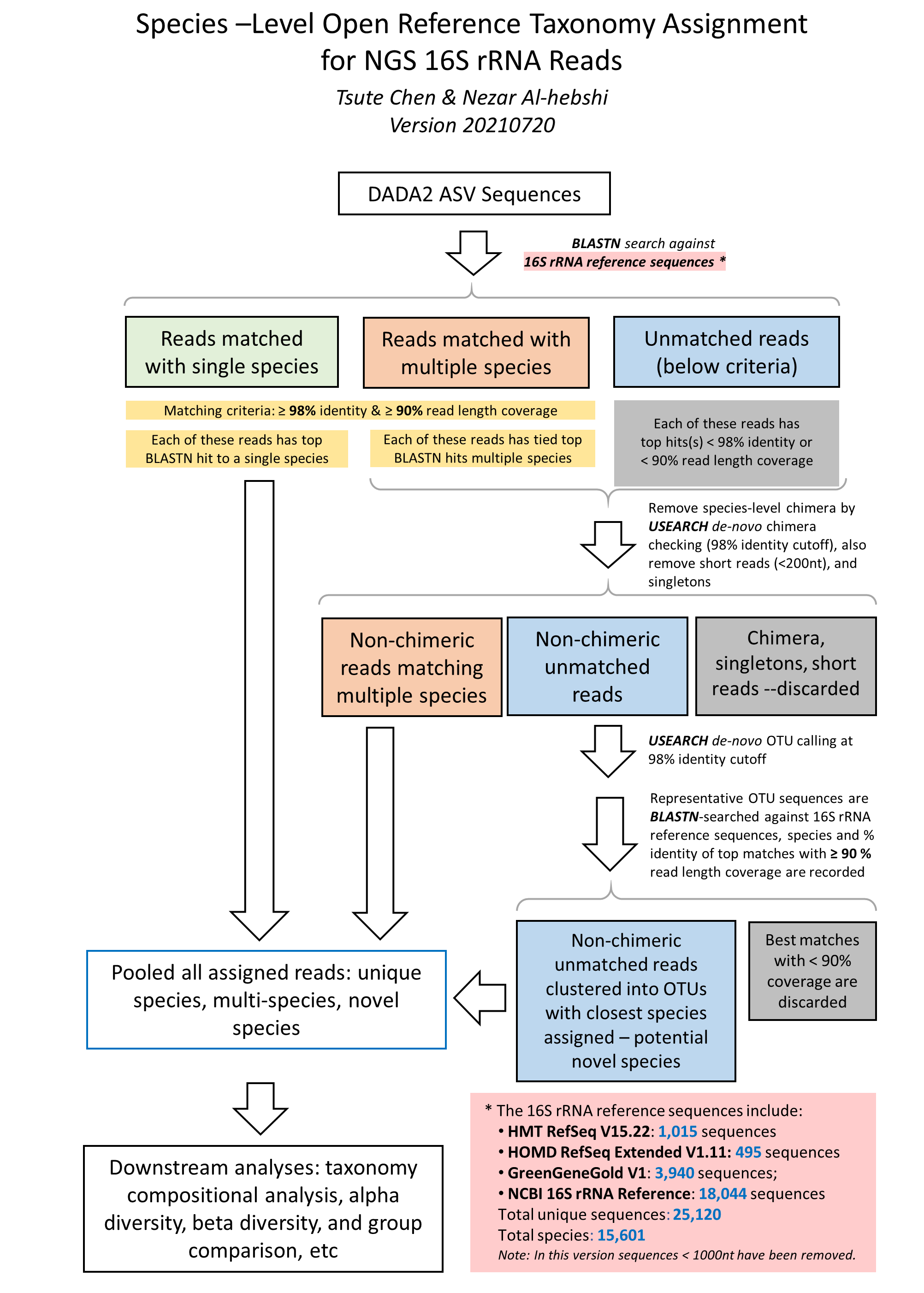











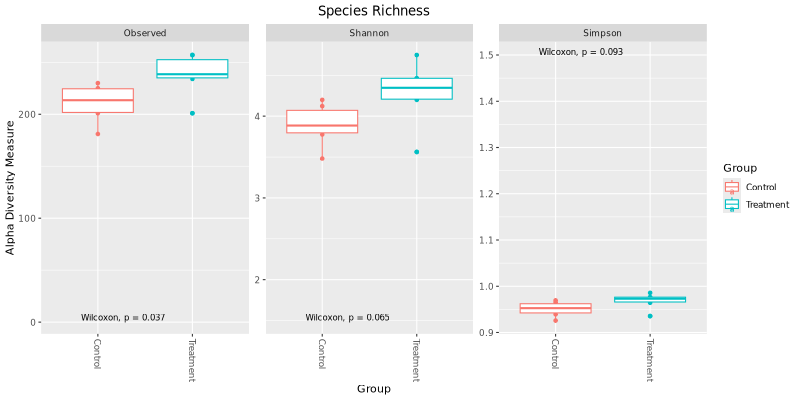{kind=link}
{kind=link}
{kind=link}