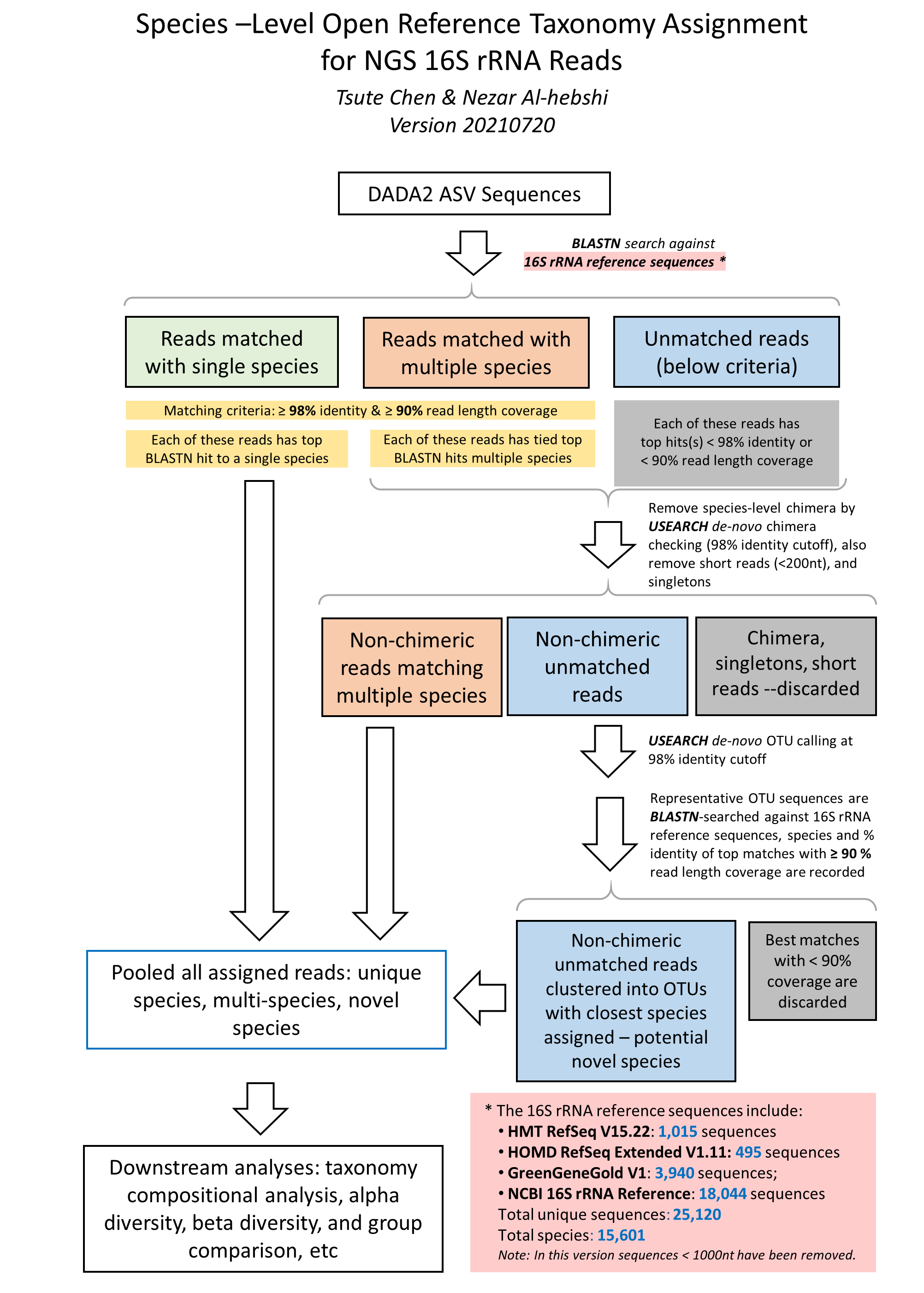
| SPID | Taxonomy | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 |
|---|
| SP10 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Bacillus;sp._str._BT1BCT2 | 0 | 0 | 2 | 1 | 0 | 7 | 2 | 0 |
|---|
| SP100 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Terribacillus;saccharophilus | 0 | 1 | 0 | 1 | 1 | 5 | 1 | 0 |
|---|
| SP102 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;casei | 0 | 1 | 0 | 21 | 1 | 2 | 1 | 0 |
|---|
| SP103 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Marinilactibacillus;piezotolerans | 0 | 3 | 2 | 13 | 0 | 0 | 0 | 0 |
|---|
| SP104 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacterales;Budviciaceae;Pragia;fontium | 1 | 5 | 0 | 0 | 0 | 0 | 1 | 0 |
|---|
| SP105 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;sp._oral_taxon_423 | 0 | 1 | 3 | 0 | 0 | 0 | 0 | 1 |
|---|
| SP106 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Micrococcaceae;Citricoccus;nitrophenolicus | 0 | 0 | 0 | 0 | 1 | 2 | 1 | 0 |
|---|
| SP107 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;equorum | 0 | 0 | 0 | 2 | 3 | 7 | 5 | 3 |
|---|
| SP108 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Escherichia;coli | 1 | 3 | 1 | 3 | 0 | 0 | 0 | 0 |
|---|
| SP109 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Enterobacter;cloacae | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP11 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Leuconostocaceae;Weissella;paramesenteroides | 0 | 4 | 0 | 524 | 0 | 1 | 0 | 0 |
|---|
| SP110 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;gingeri | 2 | 2 | 0 | 1 | 0 | 0 | 1 | 1 |
|---|
| SP111 | Bacteria;Proteobacteria;Gammaproteobacteria;Xanthomonadales;Xanthomonadaceae;Stenotrophomonas;nitritireducens | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP112 | Bacteria;Proteobacteria;Alphaproteobacteria;Alphaproteobacteria_[O];Alphaproteobacteria_[F];Alphaproteobacteria_[G];sp._Oral_Taxon_A73 | 4 | 2 | 0 | 1 | 1 | 3 | 0 | 0 |
|---|
| SP118 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhodobacterales;Rhodobacteraceae;Rhodobacter;sphaeroides | 2 | 0 | 0 | 6 | 0 | 0 | 0 | 0 |
|---|
| SP12 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;casseliflavus | 0 | 0 | 0 | 0 | 0 | 3 | 1 | 0 |
|---|
| SP120 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Micrococcaceae;Pseudarthrobacter;oxydans | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 |
|---|
| SP129 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Micrococcaceae;Glutamicibacter;nicotianae | 0 | 3 | 0 | 3 | 1 | 4 | 3 | 0 |
|---|
| SP13 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Erwinia;billingiae | 0 | 174 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP136 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;gallinarum | 0 | 3 | 0 | 6 | 0 | 1 | 0 | 0 |
|---|
| SP137 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Lactobacillaceae;Lactobacillus;similis | 0 | 0 | 0 | 19 | 0 | 0 | 0 | 0 |
|---|
| SP14 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Yersinia;mollaretii | 47 | 1 | 24 | 98 | 0 | 0 | 1 | 1 |
|---|
| SP141 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;matsuisoli | 12 | 6 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP144 | Bacteria;Bacteroidetes;Sphingobacteriia;Sphingobacteriales;Sphingobacteriaceae;Sphingobacterium;multivorum | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP146 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;sciuri | 0 | 0 | 0 | 1 | 0 | 4 | 0 | 0 |
|---|
| SP147 | Bacteria;Proteobacteria;Alphaproteobacteria;Caulobacterales;Caulobacteraceae;Brevundimonas;diminuta | 3 | 0 | 0 | 2 | 0 | 0 | 0 | 0 |
|---|
| SP148 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Bacillus;sp._Oral_Taxon_C03 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP15 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;mosselii_Oral_Taxon_A88 | 39 | 8 | 0 | 7 | 1 | 2 | 0 | 3 |
|---|
| SP151 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;halotolerans | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP16 | Bacteria;Proteobacteria;Alphaproteobacteria;Sphingomonadales;Sphingomonadaceae;Sphingomonas;aerolata | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 |
|---|
| SP162 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Alloprevotella;tannerae | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 1 |
|---|
| SP164 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Phyllobacteriaceae;Defluvibacter;lusatiensis | 0 | 0 | 0 | 0 | 0 | 4 | 1 | 0 |
|---|
| SP165 | Bacteria;Bacteroidetes;Bacteroidia;Bacteroidales;Prevotellaceae;Prevotella;intermedia | 0 | 1 | 0 | 2 | 1 | 0 | 1 | 0 |
|---|
| SP167 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Brevibacteriaceae;Brevibacterium;picturae | 0 | 0 | 0 | 3 | 0 | 1 | 1 | 0 |
|---|
| SP169 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhodobacterales;Rhodobacteraceae;Paracoccus;marcusii_Oral_Taxon_A21 | 2 | 4 | 0 | 1 | 0 | 0 | 0 | 0 |
|---|
| SP171 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Aerococcaceae;Facklamia;tabacinasalis | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP172 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;sp._str._M1 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP173 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Chryseobacterium;polytrichastri | 1 | 3 | 3 | 17 | 0 | 0 | 0 | 0 |
|---|
| SP178 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Moraxellaceae;Acinetobacter;baumannii | 1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP183 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Hyphomicrobiaceae;Devosia;riboflavina | 3 | 0 | 0 | 4 | 0 | 0 | 0 | 0 |
|---|
| SP185 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Bacillus;clausii | 0 | 0 | 2 | 0 | 0 | 2 | 0 | 0 |
|---|
| SP196 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Jeotgalicoccus;psychrophilus | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 0 |
|---|
| SP198 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Lactobacillaceae;Lactobacillus;farraginis | 0 | 4 | 0 | 1 | 0 | 0 | 0 | 0 |
|---|
| SP2 | Bacteria;Proteobacteria;Gammaproteobacteria;Xanthomonadales;Xanthomonadaceae;Stenotrophomonas;maltophilia | 10 | 13 | 0 | 0 | 0 | 1 | 0 | 0 |
|---|
| SP20 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Klebsiella;pneumoniae | 479 | 4317 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP21 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Tetragenococcus;solitarius | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 43 |
|---|
| SP212 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Methylobacteriaceae;Methylobacterium;adhaesivum | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 |
|---|
| SP219 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Hyphomicrobiaceae;Devosia;lucknowensis | 0 | 2 | 0 | 2 | 0 | 0 | 0 | 0 |
|---|
| SP22 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Brevibacteriaceae;Brevibacterium;senegalense | 0 | 7 | 0 | 3 | 0 | 0 | 3 | 0 |
|---|
| SP223 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Microbacteriaceae;Microbacterium;oleivorans | 0 | 0 | 0 | 6 | 1 | 3 | 0 | 0 |
|---|
| SP224 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Enterobacter;sp._str._638 | 0 | 2 | 0 | 0 | 0 | 3 | 0 | 0 |
|---|
| SP226 | Bacteria;Proteobacteria;Alphabacteria;Rhizobiales;Methylobacteriaceae;Methylobacterium;sp._Oral_Taxon_B84 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
|---|
| SP23 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;lutea | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP232 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Citrobacter;koseri | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP24 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Enterobacter;cancerogenus | 1 | 35 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP243 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhodobacterales;Rhodobacteraceae;Pseudorhodobacter;wandonensis | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 |
|---|
| SP244 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Gracilibacillus;halotolerans | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP246 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Rhizobiaceae;Rhizobium;cellulosilyticus_Oral_Taxon_A34 | 0 | 0 | 0 | 0 | 2 | 2 | 2 | 0 |
|---|
| SP250 | Bacteria;Actinobacteria;Actinobacteria;Propionibacteriales;Nocardioidaceae;Nocardioides;zeae | 0 | 0 | 0 | 1 | 0 | 2 | 1 | 0 |
|---|
| SP26 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;cohnii | 0 | 0 | 0 | 1 | 3 | 5 | 6 | 101 |
|---|
| SP263 | Bacteria;Proteobacteria;Alphaproteobacteria;Sphingomonadales;Sphingomonadaceae;Sphingomonas;echinoides | 2 | 0 | 0 | 6 | 0 | 0 | 0 | 0 |
|---|
| SP28 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Klebsiella;sp._Oral_Taxon_A36 | 1 | 2 | 0 | 0 | 0 | 1 | 0 | 0 |
|---|
| SP29 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;stutzeri | 1 | 4 | 0 | 12 | 0 | 1 | 1 | 0 |
|---|
| SP3 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;arlettae | 0 | 7 | 3 | 44 | 308 | 552 | 641 | 4886 |
|---|
| SP30 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;fluorescens | 44 | 2 | 42 | 139 | 1 | 2 | 0 | 3 |
|---|
| SP32 | Bacteria;Proteobacteria;Gammaproteobacteria;Oceanospirillales;Halomonadaceae;Halomonas;nanhaiensis | 0 | 23 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP33 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;straminea | 7 | 12 | 0 | 15 | 0 | 0 | 0 | 0 |
|---|
| SP34 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Brevibacteriaceae;Brevibacterium;avium | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 581 |
|---|
| SP35 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Pantoea;ananatis | 41 | 7 | 0 | 4 | 1 | 1 | 1 | 0 |
|---|
| SP36 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Methylobacteriaceae;Methylobacterium;goesingense | 1 | 3 | 0 | 2 | 0 | 0 | 0 | 0 |
|---|
| SP38 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Lactobacillaceae;Lactobacillus;pantheris | 0 | 0 | 0 | 178 | 0 | 0 | 0 | 0 |
|---|
| SP39 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Rhizobiaceae;Agrobacterium;tumefaciens | 3 | 0 | 0 | 8 | 0 | 1 | 1 | 0 |
|---|
| SP4 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Tetragenococcus;halophilus | 0 | 0 | 0 | 5 | 3490 | 2143 | 653 | 2 |
|---|
| SP41 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhizobiales;Hyphomicrobiaceae;Devosia;soli | 1 | 2 | 0 | 0 | 0 | 2 | 0 | 0 |
|---|
| SP42 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Leuconostocaceae;Weissella;cibaria | 0 | 29 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP44 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Streptococcaceae;Streptococcus;dentisani | 0 | 0 | 0 | 1 | 1 | 2 | 0 | 0 |
|---|
| SP45 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;saprophyticus | 0 | 7 | 0 | 2 | 18 | 11 | 27 | 4 |
|---|
| SP46 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;flavescens | 0 | 2 | 0 | 10 | 0 | 0 | 0 | 0 |
|---|
| SP47 | Plantae;Angiosperms;Eudicots;Malpighiales;Euphorbiaceae;Manihot;esculenta_Oral_Taxon_C60 | 166 | 88 | 2 | 8 | 1 | 3 | 9 | 1 |
|---|
| SP48 | Plantae;Angiosperms;Magnoliids;Laurales;Calycanthaceae;Calycanthus;floridus_Oral_Taxon_D07 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP49 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Nocardiaceae;Rhodococcus;fascians | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 |
|---|
| SP51 | Bacteria;Proteobacteria;Gammaproteobacteria;Xanthomonadales;Xanthomonadaceae;Stenotrophomonas;pavanii | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP52 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Bacillus;licheniformis | 0 | 0 | 2 | 0 | 0 | 7 | 11 | 0 |
|---|
| SP53 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Microbacteriaceae;Agrococcus;terreus | 0 | 0 | 0 | 32 | 1 | 1 | 0 | 1 |
|---|
| SP55 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Terribacillus;halophilus | 2 | 12 | 2 | 1 | 0 | 0 | 0 | 0 |
|---|
| SP6 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Lactobacillaceae;Lactobacillus;pobuzihii | 1 | 6 | 0 | 0 | 0 | 0 | 0 | 44 |
|---|
| SP62 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;sp._clonebottae7 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 69 |
|---|
| SP63 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Citrobacter;youngae | 2 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP64 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Microbacteriaceae;Pseudoclavibacter;helvolus | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 0 |
|---|
| SP65 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;pseudoalcaligenes | 21 | 3 | 0 | 1 | 0 | 0 | 1 | 0 |
|---|
| SP67 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Lactobacillaceae;Lactobacillus;vaccinostercus | 0 | 0 | 0 | 84 | 0 | 0 | 0 | 0 |
|---|
| SP69 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;argentinensis | 2 | 7 | 0 | 34 | 0 | 0 | 0 | 0 |
|---|
| SP7 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Bacillus;pumilus | 1 | 3 | 3 | 4 | 5 | 9 | 24 | 2 |
|---|
| SP70 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;putida | 0 | 1 | 0 | 5 | 0 | 0 | 0 | 0 |
|---|
| SP71 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;ammoniagenes | 0 | 0 | 0 | 0 | 2 | 3 | 1 | 44 |
|---|
| SP74 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Serratia;proteamaculans | 4 | 0 | 6 | 8 | 1 | 0 | 0 | 0 |
|---|
| SP77 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Enterobacter;hormaechei | 0 | 11 | 0 | 2 | 0 | 0 | 0 | 0 |
|---|
| SP8 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Granulicatella;sp._Oral_Taxon_D03 | 6 | 117 | 1 | 17 | 5 | 10 | 5 | 2 |
|---|
| SP83 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Moraxellaceae;Acinetobacter;sp._Oral_Taxon_D29 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SP88 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Micrococcaceae;Micrococcus;luteus_Oral_Taxon_H68 | 0 | 0 | 1 | 3 | 2 | 0 | 0 | 0 |
|---|
| SP89 | Bacteria;Firmicutes;Bacilli;Bacillales;Bacillaceae;Bacillus;subtilis | 0 | 8 | 0 | 2 | 0 | 2 | 2 | 0 |
|---|
| SP91 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Dermabacteraceae;Brachybacterium;sp._Oral_Taxon_A83 | 0 | 1 | 0 | 3 | 4 | 19 | 13 | 1 |
|---|
| SP93 | Bacteria;Proteobacteria;Alphaproteobacteria;Sphingomonadales;Sphingomonadaceae;Sphingomonas;sanguinis | 8 | 2 | 0 | 0 | 0 | 1 | 0 | 0 |
|---|
| SP94 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Microbacteriaceae;Microbacterium;sp._Oral_Taxon_C11 | 0 | 0 | 0 | 0 | 0 | 2 | 3 | 0 |
|---|
| SP96 | Bacteria;Proteobacteria;Gammaproteobacteria;Xanthomonadales;Xanthomonadaceae;Lysobacter;spongiicola | 0 | 3 | 0 | 1 | 0 | 0 | 0 | 0 |
|---|
| SP97 | Bacteria;Proteobacteria;Alphaproteobacteria;Rhodobacterales;Rhodobacteraceae;Paracoccus;marcusii_Oral_Taxon_D41 | 9 | 3 | 0 | 9 | 0 | 1 | 0 | 0 |
|---|
| SP99 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;punonensis | 0 | 0 | 0 | 36 | 0 | 1 | 0 | 0 |
|---|
| SPN1 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Micrococcaceae;Kocuria;sp._oral_taxon_189_nov_88.732% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 31 |
|---|
| SPN10 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Dolosigranulum;pigrum_nov_85.461% | 0 | 0 | 0 | 4 | 2317 | 3605 | 2797 | 516 |
|---|
| SPN11 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Dermacoccaceae;Kytococcus;sedentarius_nov_89.085% | 0 | 0 | 0 | 0 | 1 | 5 | 3 | 0 |
|---|
| SPN12 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;warneri_nov_92.527% | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 5 |
|---|
| SPN13 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Granulicatella;elegans_nov_82.456% | 0 | 0 | 0 | 0 | 46 | 0 | 2508 | 43 |
|---|
| SPN14 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Capnocytophaga;sp._oral_taxon_338_nov_81.690% | 0 | 9 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPN15 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Micrococcaceae;Kocuria;sp._oral_taxon_189_nov_90.559% | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 8 |
|---|
| SPN16 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Micrococcaceae;Kocuria;sp._oral_taxon_189_nov_88.298% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 |
|---|
| SPN17 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Intrasporangiaceae;Arsenicicoccus;bolidensis_nov_87.455% | 0 | 1 | 0 | 0 | 1 | 3 | 3 | 0 |
|---|
| SPN18 | Bacteria;Bacteroidetes;Flavobacteriia;Flavobacteriales;Flavobacteriaceae;Bergeyella;sp._oral_taxon_422_nov_91.729% | 2 | 0 | 0 | 5 | 0 | 0 | 0 | 0 |
|---|
| SPN19 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;tuscaniense_nov_90.877% | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 |
|---|
| SPN2 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Dolosigranulum;pigrum_nov_85.512% | 0 | 0 | 0 | 1 | 1684 | 3235 | 2256 | 488 |
|---|
| SPN20 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Kluyvera;ascorbata_nov_95.374% | 106 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPN21 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Mycobacteriaceae;Mycobacterium;neoaurum_nov_86.022% | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 |
|---|
| SPN22 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Alloiococcus;otitis_nov_79.775% | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 0 |
|---|
| SPN23 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;saccharolyticus_nov_87.633% | 0 | 0 | 0 | 3 | 1213 | 464 | 166 | 0 |
|---|
| SPN24 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Micrococcaceae;Kocuria;sp._oral_taxon_189_nov_88.849% | 0 | 0 | 0 | 0 | 0 | 1 | 3 | 0 |
|---|
| SPN25 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Dermacoccaceae;Kytococcus;sedentarius_nov_85.547% | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 1 |
|---|
| SPN26 | Bacteria;Proteobacteria;Alphaproteobacteria;Sphingomonadales;Sphingomonadaceae;Porphyrobacter;tepidarius_nov_93.238% | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 |
|---|
| SPN27 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;saccharolyticus_nov_87.986% | 0 | 0 | 0 | 0 | 3 | 1 | 0 | 0 |
|---|
| SPN3 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;tuscaniense_nov_91.873% | 0 | 29 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPN30 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Micrococcaceae;Kocuria;sp._oral_taxon_189_nov_90.071% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 99 |
|---|
| SPN35 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;saccharolyticus_nov_86.713% | 0 | 0 | 0 | 2 | 1208 | 259 | 111 | 0 |
|---|
| SPN4 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Actinomycetaceae;Actinomyces;odontolyticus_nov_88.621% | 0 | 0 | 0 | 0 | 8 | 14 | 1 | 0 |
|---|
| SPN41 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;saccharolyticus_nov_86.415% | 0 | 0 | 0 | 0 | 49 | 42 | 5 | 0 |
|---|
| SPN47 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Dolosigranulum;pigrum_nov_83.509% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 286 |
|---|
| SPN5 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Dolosigranulum;pigrum_nov_84.397% | 0 | 0 | 0 | 0 | 2 | 0 | 19 | 0 |
|---|
| SPN52 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Dermacoccaceae;Kytococcus;sedentarius_nov_89.437% | 0 | 0 | 0 | 0 | 8 | 25 | 36 | 0 |
|---|
| SPN58 | Bacteria;Proteobacteria;Gammaproteobacteria;Enterobacteriales;Enterobacteriaceae;Enterobacter;cancerogenus_nov_93.571% | 226 | 5 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPN59 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;saccharolyticus_nov_87.589% | 0 | 0 | 0 | 0 | 82 | 57 | 8 | 0 |
|---|
| SPN6 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;saccharolyticus_nov_88.339% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 19 |
|---|
| SPN60 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;tuscaniense_nov_90.071% | 0 | 12 | 0 | 1 | 3 | 5 | 2 | 91 |
|---|
| SPN61 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;mucifaciens_nov_93.548% | 4 | 0 | 0 | 34 | 2 | 19 | 8 | 0 |
|---|
| SPN62 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Lactobacillaceae;Lactobacillus;kisonensis_nov_86.926% | 0 | 0 | 0 | 56 | 0 | 0 | 0 | 0 |
|---|
| SPN63 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Carnobacteriaceae;Granulicatella;adiacens_nov_83.916% | 0 | 0 | 0 | 0 | 29 | 14 | 6 | 0 |
|---|
| SPN64 | Bacteria;Actinobacteria;Actinobacteria;Micrococcales;Sanguibacteraceae;Sanguibacter;keddieii_nov_87.943% | 0 | 0 | 0 | 0 | 3 | 3 | 2 | 32 |
|---|
| SPN7 | Bacteria;Actinobacteria;Actinobacteria;Corynebacteriales;Corynebacteriaceae;Corynebacterium;tuscaniense_nov_92.199% | 0 | 16 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPN8 | Bacteria;Firmicutes;Bacilli;Lactobacillales;Enterococcaceae;Enterococcus;saccharolyticus_nov_86.742% | 0 | 0 | 0 | 0 | 5 | 3 | 2 | 0 |
|---|
| SPN9 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;aeruginosa_nov_89.680% | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPP5 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;multispecies_spp5_2 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 132 |
|---|
| SPP7 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;multispecies_spp7_3 | 14 | 26 | 0 | 27 | 0 | 0 | 0 | 0 |
|---|
| SPP8 | Bacteria;Proteobacteria;Gammaproteobacteria;Xanthomonadales;Xanthomonadaceae;Lysobacter;multispecies_spp8_3 | 2 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPPN1 | Bacteria;Actinobacteria;Actinobacteria;Actinomycetales;Actinomycetaceae;Actinomyces;multispecies_sppn1_2_nov_88.028% | 0 | 0 | 0 | 0 | 2 | 15 | 10 | 4 |
|---|
| SPPN2 | Bacteria;Firmicutes;Bacilli;Bacillales;Staphylococcaceae;Staphylococcus;multispecies_sppn2_2_nov_83.214% | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 |
|---|
| SPPN3 | Bacteria;Proteobacteria;Gammaproteobacteria;Pseudomonadales;Pseudomonadaceae;Pseudomonas;multispecies_sppn3_2_nov_97.857% | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|













{kind=link}
{kind=link}
{kind=link}